Overview
Metadata ingestion is the process in which rudol frequently connects to your data sources and extracts all available metadata. After the ingestion engine processes all the metadata you will have a unified Data Catalog collecting all catalog items and allowing your team members to collaborate in a single source of truth.
The following connectors are available:
Database
Data Warehouse
Business Intelligence
- Looker
- Looker Studio (former Google Data Studio)
- Tableau
- Microsoft Power BI
- Strategy
More connectors are coming and you can ask your own.
Each connector has an specific set of connection parameters, refer to the connector docs to find out more about each technology.
Add a Datasource
To get started add your first datasource from the Datasources section clicking on the + Datasource button and choose Cloud based on Connector architecture.
On premise connectors allow you to configure an extra layer of security installing a Docker agent to keep access credentials completely managed by you. This architecture is not available yet.
Choose your connector technology and complete all required connection parameters, refer to the connector docs to find out more about each parameter. Choose a value for Scanning frequency that matches your team's workflow to minimize unnecessary connections to your data source.
Optionally you can add tags to help filter items faster when searching.
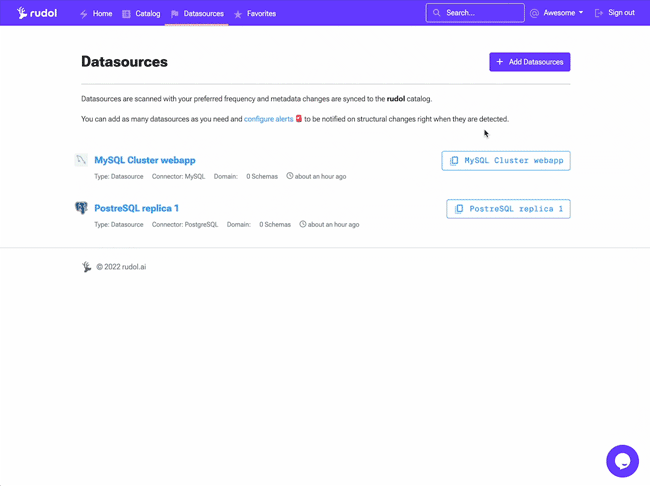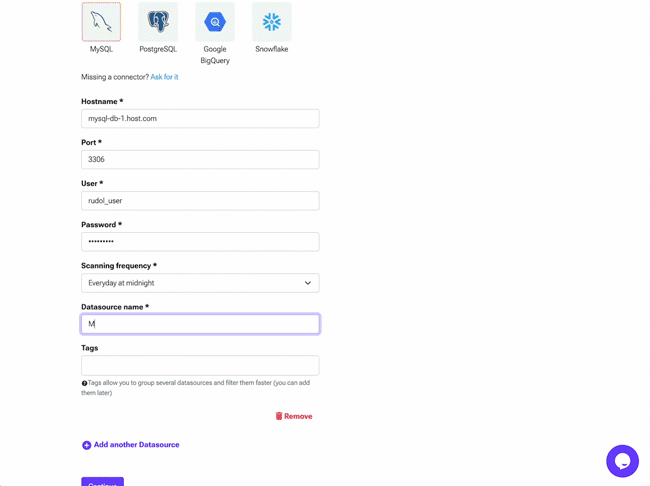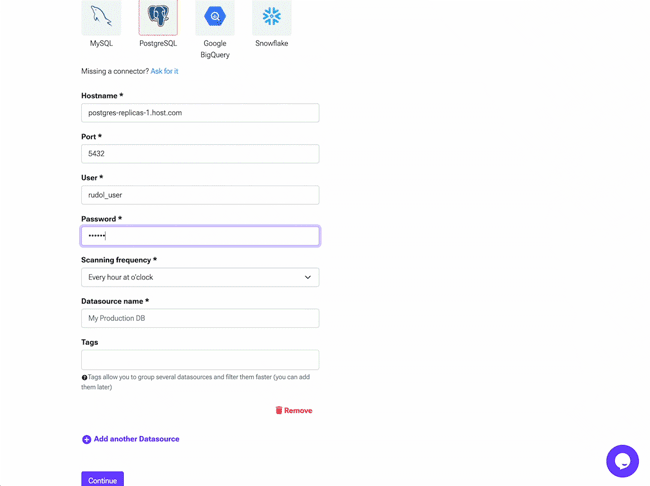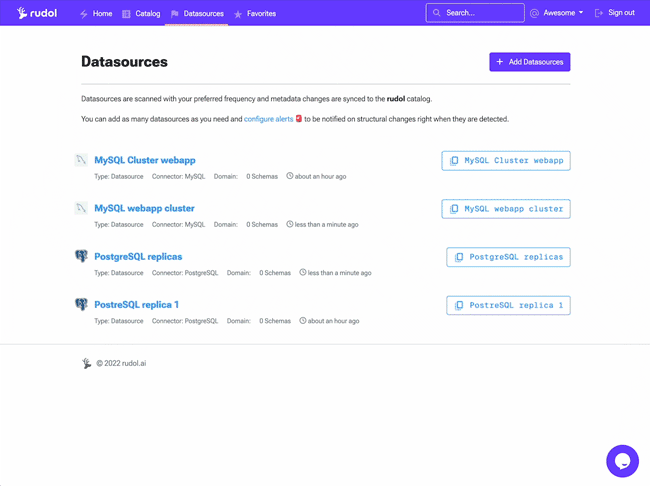
Metadata ingestion and sync takes about 2-3 minutes to complete. You'll be able to see your catalog items once it has finished.
Importing existing items description
If your catalog items (schemas, tables, columns) already have some description it will be imported to rudol and you'll be able to see it under the Description tab.
If you edit this documentation using the markdown editor the underlying data source won't be affected because data item's sync is one-way only.
If you edit your catalog item's source description but you've already added documentation it won't have any effect since rudol documentation has priority.